
Pembelajaran Mesin (Machine Learning) dalam Dunia Matematik: Dari Data hingga Persamaan Pembezaan
Pembelajaran Mesin (Machine Learning) dalam Dunia Matematik: Dari Data hingga Persamaan Pembezaan
Penulis: Dr. Maharani Abu Bakar
Pensyarah Kanan,
Jabatan Matematik, Fakulti Sains Komputer dan Matematik
Universiti Malaysia Terengganu
Dalam dunia matematik moden, semakin banyak masalah yang tidak lagi cukup diselesaikan hanya dengan pen dan kertas. Masalah-masalah kompleks daripada permodelan penyebaran penyakit, simulasi aliran bendalir, hinggalah analisis risiko kewangan, sering memerlukan penyelesaian yang melangkaui kaedah tradisional.
Salah satu pendekatan yang kini merevolusi bidang ini ialah Machine Learning (ML), atau pembelajaran mesin. Topik inilah yang penulis bawakan dalam kuliah umum di Universitas Islam Negeri Sultan Syarif Kasim Riau baru-baru ini, dengan tajuk “Machine Learning for Mathematical Minds: From Data to Differential Equations.”
Memahami Pembelajaran Mesin dari Perspektif Matematik
Pada asasnya, Machine Learning (ML) mengajar komputer mencari pola dalam data tanpa kita perlu menetapkan setiap langkah secara eksplisit. Ini berbeza daripada pendekatan pengaturcaraan klasik yang perlu memberi arahan terperinci satu per satu. Namun, di balik “keajaiban” ML, tersembunyi kerangka matematik yang sangat kukuh.
Algebra Linear: Bahasa Data
Dalam dunia ML, hampir semua maklumat sama ada gambar, teks atau angka jualan yang pada akhirnya diterjemah menjadi deretan nombor yang tersusun dalam bentuk vektor dan matriks. Algebra linear menjadi asas bagaimana komputer menyusun, memanipulasi, dan memproses data ini. Misalnya dalam mengenal pasti corak dalam ribuan imej, operasi matriks membantu “mengekstrak” ciri penting yang membezakan satu objek dengan objek lain.
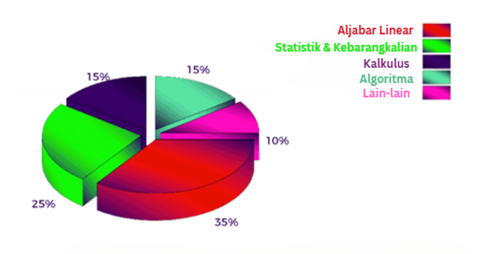
Kalkulus: Mengawal Proses Pembelajaran
Kalkulus pula memberi ML keupayaan untuk belajar secara berperingkat. Dengan konsep kadar perubahan, ML boleh mengukur sejauh mana “kesalahan” dalam tekaan awalnya, lalu memperbaiki diri sedikit demi sedikit. Proses ini berulang jutaan kali sehingga model mencapai ketepatan yang dikehendaki. Kalau diibaratkan, kalkulus adalah kompas yang memandu model untuk perlahan-lahan menuju jawapan yang paling hampir dengan kebenaran.
Kebarangkalian & Statistik: Membuat Keputusan dalam Ketidakpastian
Satu lagi tunjang penting ialah teori kebarangkalian. Dalam dunia sebenar, data sering datang dengan unsur rawak atau ketidaktentuan. ML menggunakan prinsip statistik untuk menilai seberapa yakin ia dengan sesuatu ramalan, dan membezakan pola sebenar daripada sekadar kebetulan. Bayangkan seorang doktor menggunakan ML untuk meramal risiko penyakit, dia tentu mahu tahu bukan saja keputusan “positif atau negatif”, tetapi juga tahap keyakinan di sebalik keputusan itu. Inilah hasil kekuatan statistik dalam ML.
Jenis-Jenis Utama Machine Learning
Secara umum, Machine Learning boleh dibahagikan kepada tiga kategori utama, bergantung kepada cara sistem belajar daripada data:
- Pembelajaran terselia (Supervised Learning):
Dalam pendekatan ini, komputer dilatih menggunakan data yang sudah berlabel. Contohnya, set data mungkin mengandungi gambar buah-buahan bersama label “epal” atau “pisang”, lalu sistem belajar membezakan ciri-ciri setiap jenis. Kaedah ini sangat sesuai untuk masalah ramalan (regresi) atau pengelasan (klasifikasi) seperti mengenal pasti risiko penyakit atau meramal harga pasaran.
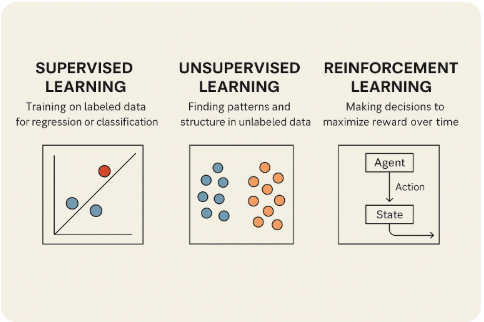
- Pembelajaran tidak terselia (Unsupervised Learning):
Berbeza dengan pembelajaran terselia, pendekatan ini digunakan apabila data tidak mempunyai label. Sistem akan cuba mencari struktur atau pola tersembunyi dalam data tersebut. Contohnya teknik pengelompokan (clustering) k-Means digunakan untuk mengelompokkan pelanggan dengan corak pembelian yang serupa, atau teknik pengurangan dimensi untuk memadatkan data kompleks kepada maklumat paling penting. - Pembelajaran peneguhan (Reinforcement Learning):
Pendekatan ini mirip cara manusia belajar daripada pengalaman dan ganjaran. Sistem membuat keputusan, menerima ganjaran atau penalti, lalu memperbaiki tindakannya pada masa depan. Kaedah ini banyak digunakan dalam bidang robotik, sistem kawalan automatik, serta dalam pembangunan program permainan yang mampu menewaskan pemain manusia.
Dari Data ke Penyelesaian Persamaan Pembezaan
Salah satu perkembangan yang paling menarik dalam dunia Machine Learning (ML) hari ini ialah bagaimana pendekatan ini, khususnya melalui Artificial Neural Networks (ANN), dapat digunakan untuk menyelesaikan persamaan matematik yang secara tradisionalnya dianggap rumit iaitu persamaan pembezaan.
Apa itu Persamaan Pembezaan?
Persamaan pembezaan muncul di hampir setiap sudut sains dan kejuruteraan. Dalam bentuk paling mudahnya, persamaan pembezaan biasa (ODE) menggambarkan bagaimana sesuatu kuantiti berubah berbanding satu pemboleh ubah, misalnya masa. Contohnya kadar pertumbuhan populasi, kadar pereputan bahan radioaktif, dan model penyakit berjangkit SEIR.
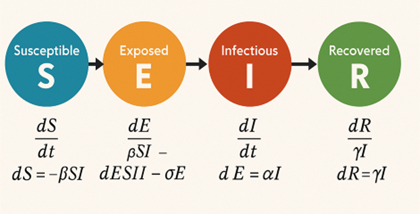
Sementara itu, persamaan pembezaan separa (PDE) pula menggambarkan perubahan bergantung kepada lebih daripada satu pemboleh ubah, seperti bagaimana suhu merebak dalam sebatang logam atau bagaimana gelombang bergerak di permukaan air.
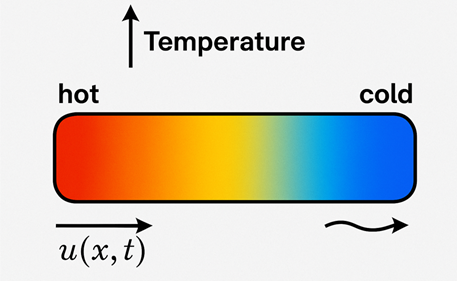
Selama ini, saintis menyelesaikan ODE dan PDE menggunakan kaedah analitik dan pendekatan numerik seperti kaedah Euler, Runge-Kutta, dan elemen terhingga (FEM). Namun kaedah ini biasanya memerlukan pembahagian kawasan masalah kepada grid atau nod yang boleh menjadi sangat mahal dari segi masa pengiraan, terutamanya untuk masalah kompleks.
ANN Sebagai Alternatif Pintar untuk Menyelesaikan Persamaan Pembezaan
Dalam pendekatan tradisional, untuk menyelesaikan persamaan pembezaan sama ada persamaan pembezaan biasa (ODE) mahupun persamaan pembezaan separa (PDE) , kita biasanya memecahkan domain persamaan kepada grid atau mesh yang sangat halus. Ini dilakukan supaya kita boleh menghampiri derivatif yang terdapat dalam persamaan itu menggunakan kaedah diskret, seperti perbezaan terhingga (finite difference) atau elemen terhingga (finite element method, FEM).
Sebagai contoh, jika anda ingin mengira bagaimana haba mengalir melalui batang logam (iaitu masalah PDE klasik, persamaan haba), makaand perlu membahagikan batang tersebut kepada segmen-segmen kecil, lalu suhu dikira pada setiap titik grid menggunakan formula perbezaan terhingga untuk menghampiri kadar perubahan suhu. Proses ini perlu diulang di sepanjang batang dan pada setiap langkah masa sehingga keseluruhan simulasi selesai.
Proses ini menjadi sangat mahal dalam hal pengiraan masa komputasi. Lebih lanjut, lebih halus grid yang digunakan, lebih banyak titik yang perlu dikira, dan dalam simulasi numerik, langkah masa (time step) juga perlu cukup kecil supaya simulasi stabil. Ini menambahkan kos pengiraan. Bagi masalah tiga dimensi, jumlah titik boleh meningkat secara eksponen, menyebabkan keperluan memori dan masa pemprosesan melambung tinggi. Selain itu, jika domain yang dikaji mempunyai bentuk yang pelik atau tidak seragam, misalnya rekabentuk sayap kapal terbang atau tisu biologi yang rumit, membina grid menjadi lebih sukar dan memerlukan perisian grid generation khas.
Inilah sebabnya mengapa muncul pendekatan baru seperti penggunaan Artificial Neural Networks (ANN) yang boleh menjadi alternatif yang sangat menarik. ANN dapat terus menghampiri penyelesaian fungsi di seluruh domain secara berterusan, tanpa perlu memecah kawasan masalah kepada grid yang padat. Kaedah ini juga lebih mudah disesuaikan kepada masalah berdimensi tinggi dan geometri yang kompleks sekaligus mengurangkan keperluan sumber komputasi yang sangat besar.
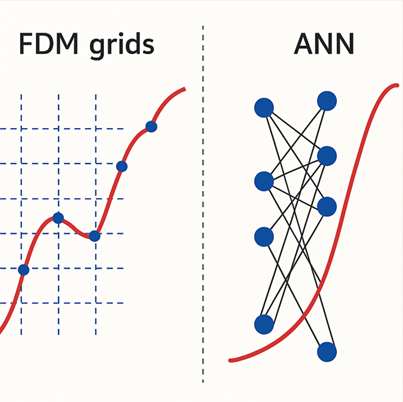
Bagaimana Ia Berfungsi?
Secara konsepnya, pendekatan ini boleh digambarkan dalam beberapa langkah utama:
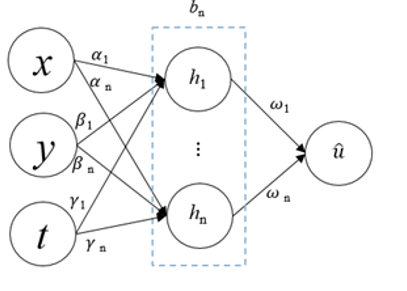
1-Mengambil input (seperti x dan t):
ANN menerima pemboleh ubah bebas masalah, contohnya dalam PDE, x boleh mewakili kedudukan dan t mewakili masa.
2-Menghasilkan output anggaran penyelesaian:
Output ANN bukan sekadar kelas atau nilai ramalan biasa, tetapi bertindak sebagai anggaran fungsi penyelesaian, misalnya u(x, t).
3-Mengira kadar perubahan secara automatik:
Untuk memastikan penyelesaian memenuhi persamaan pembezaan, ANN perlu tahu bagaimana u(x, t) berubah apabila x atau t berubah. Ini dilakukan dengan automatic differentiation, sebuah teknik yang membolehkan pengiraan turunan terus dari struktur rangkaian, tanpa memerlukan formula perbezaan terhingga pada grid.
4-Mengoptimumkan fungsi kos yang memaksa ANN mematuhi ODE/PDE:
Fungsi kos di sini dirancang supaya ia mengukur sejauh mana ANN melanggar persamaan pembezaan atau syarat sempadan. Dalam proses latihan, ANN akan melaraskan parameternya untuk meminimumkan pelanggaran ini dengan kata lain, ANN “belajar” menjadi fungsi yang menyelesaikan persamaan.
Projek Tahun Akhir bagi Bidang Matematik UMT
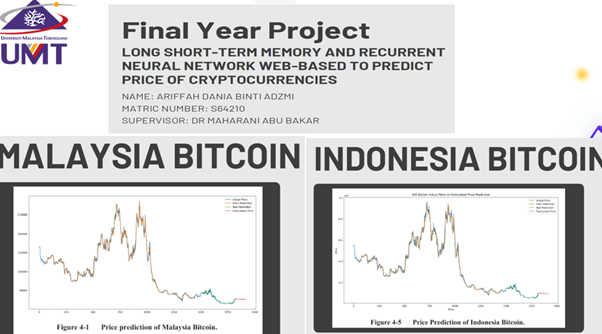
Sejak melibatkan diri di dunia Machine Learning iaitu bermula pada tahun 2020, penulis telah menyelia pelajar-pelajar tahun ketiga dengan projek ML. Alhamdulillah, mereka sangat tertarik dan bersemangat dengan topik-topik ML yang bervariasi, seperti Machine Learning on Comorbidity Prediction using Support Vector Regression, Long Short-Term Memory and Recurrent Neural Network to Predict Price of Bitcoin, SVR and GRNN in Prediction Inbound Tourism in Malaysia, dan Enhanced Machine Learning in Solving Modified SEIR Model based on Chunk-PINN. Bahkan, mereka berjaya ke tahap yang menghasilkan web-based, diantaranya Long Short-Term Memory and Recurrent Neural Network Web-Based, SVR-GRNN Web-Based, dan Hybrid NN Models Web-Based for Stock Returns Forecasting. Hal yang menggembirakan iaitu ketika dua pelajar tahun akhir lulus dalam seleksi mengikuti event besar “Student Research Day” di UMT pada bulan Jun 2025 lalu.
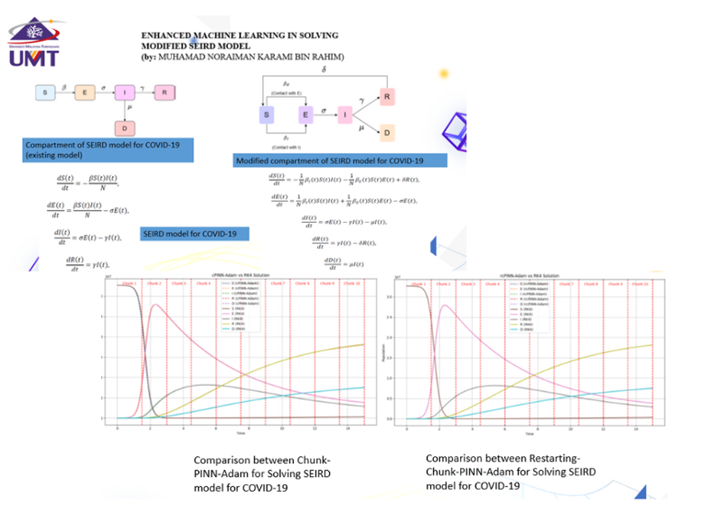

Masa Depan Matematik adalah Data-Driven
Perjalanan ML dari penyelesaian masalah data biasa hingga ke menyelesaikan persamaan pembezaan jelas menunjukkan betapa pentingnya peranan matematik. Dalam era moden ini, ahli matematik mempunyai kelebihan besar: kefahaman mendalam terhadap struktur persamaan dan teori, yang menjadi asas kepada algoritma ML.
Dengan tulisan ringkas ini, penulis berharap ia mampu menanam rasa ingin tahu dalam kalangan pelajar untuk meneroka bagaimana mereka boleh menggunakan latar belakang matematik mereka untuk membina model ML, seterusnya menyumbang kepada penyelesaian masalah kompleks di dunia nyata.
Biodata
 Maharani Abu Bakar memperoleh ijazah PhD dalam Sains Matematik dari Universiti Essex pada tahun 2015. Beliau kini bertugas sebagai pensyarah kanan di Jabatan Matematik, Fakulti Sains Komputer dan Matematik, Universiti Malaysia Terengganu (UMT). Beliau juga merupakan ahli Special Interest Group Modelling and Data Analytics, UMT. Bidang penyelidikan beliau merangkumi artificial neural networks (ANN), Pembelajaran Mesin, dan Analisis Berangka. Baru-baru ini, beliau menumpukan penyelidikan kepada model hibrid rangkaian neural berasaskan fizik untuk dimensi tinggi persamaan pembezaan. Beliau telah menulis dan menjadi penulis bersama lebih daripada 30 artikel penyelidikan dalam jurnal berimpak tinggi seperti Elsevier, IEEE, dan penerbit Taylor & Francis. Beliau juga merupakan editor bagi prosiding persidangan AIP, Journal of Mathematics and System Informatics (JMSI) di bawah UMT, serta Journal of Computers and Electrical Engineering di bawah Elsevier. Beliau aktif menjalin rangkaian dengan penyelidik antarabangsa di seluruh dunia.
Maharani Abu Bakar memperoleh ijazah PhD dalam Sains Matematik dari Universiti Essex pada tahun 2015. Beliau kini bertugas sebagai pensyarah kanan di Jabatan Matematik, Fakulti Sains Komputer dan Matematik, Universiti Malaysia Terengganu (UMT). Beliau juga merupakan ahli Special Interest Group Modelling and Data Analytics, UMT. Bidang penyelidikan beliau merangkumi artificial neural networks (ANN), Pembelajaran Mesin, dan Analisis Berangka. Baru-baru ini, beliau menumpukan penyelidikan kepada model hibrid rangkaian neural berasaskan fizik untuk dimensi tinggi persamaan pembezaan. Beliau telah menulis dan menjadi penulis bersama lebih daripada 30 artikel penyelidikan dalam jurnal berimpak tinggi seperti Elsevier, IEEE, dan penerbit Taylor & Francis. Beliau juga merupakan editor bagi prosiding persidangan AIP, Journal of Mathematics and System Informatics (JMSI) di bawah UMT, serta Journal of Computers and Electrical Engineering di bawah Elsevier. Beliau aktif menjalin rangkaian dengan penyelidik antarabangsa di seluruh dunia.




{kind=link}