
Penulis: Prof. Madya Dr. Nurulkamal Masseran
Pensyarah Kanan
Jabatan Sains Matematik, Universiti Kebangsaan Malaysia
Dalam era sains data pada hari ini, kita dihimpuni dengan pelbagai jenis data dalam kuantiti yang besar. Selari dengan itu, kebanyakan institusi pada masa kini pasti akan menyimpan set data raya (big data) bagi tujuan untuk perancangan dan pembuatan keputusan yang lebih bermakna. Ini menjadikan tugasan menguruskan dan menjalankan analisis data bukanlah aktiviti pekerjaan yang asing lagi bagi kebanyakan individu. Namun, malangnya tidak ramai individu yang benar-benar memiliki latar belakang yang kukuh berkaitan ilmu pengetahuan yang baik dalam disiplin bidang ilmu statistik dan sains data. Keadaan ini menjadikan analisis statistik yang dijalankan mungkin tidak mendalam dan kadang-kala kurang tepat. Malah, apa yang lebih membimbangkan, mereka mungkin akan terkeliru dengan tingkah laku data, sekaligus memasuki perangkap “Paradoks Simpson”. Perkara ini sangat berbahaya kerana maklumat yang dihasilkan tanpa menyedari fenomena “Paradoks Simpson” dalam analisis yang dijalankan akan menyebabkan penghasilan maklumat yang palsu. Secara tidak langsung, sebarang perancangan dan keputusan yang dibuat daripada maklumat yang palsu ini akan membawa implikasi yang buruk terhadap institusi tersebut.
Apakah itu Paradoks Simpson?
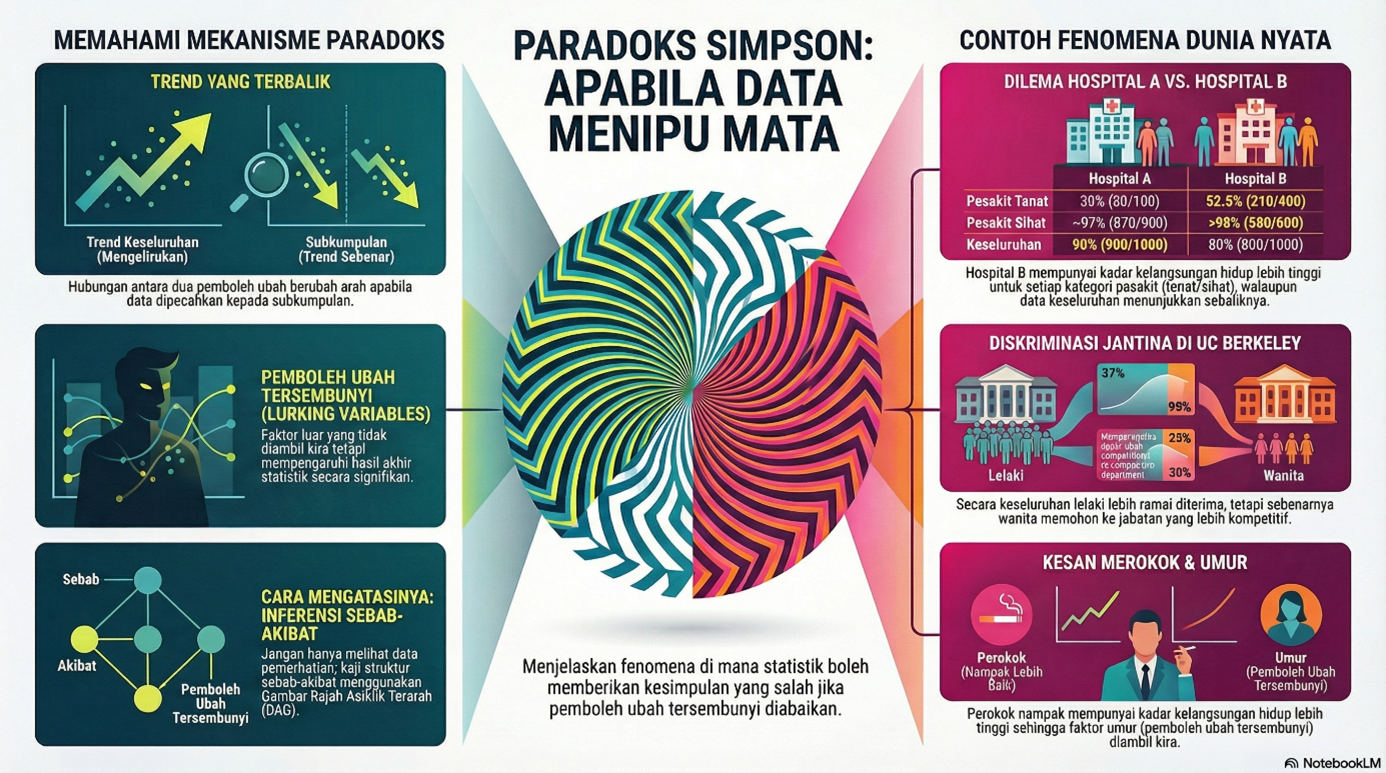
Sebahagian orang pasti akan tersilap anggap yang fenomena “Paradoks Simpson” mungkin berkait dengan kartun “The Simpsons” yang popular dikalangan masyarakat seluruh dunia. Namun, sebaliknya ianya tidak ada kena mengena dengan kartun tersebut. Sebutan “Paradoks Simpson” ini dinamakan sempena nama ahli statistik British iaitu Edward H. Simpson yang menjadi pelopor utama dalam menghuraikan fenomena “Paradoks Simpson” ini secara formal pada sekitar tahun 1951. Umumnya, fenomena paradoks Simpson berlaku apabila trend yang muncul dalam beberapa kumpulan data yang berasingan adalah bersongsangan apabila kumpulan-kumpulan tersebut digabungkan. Dalam erti kata lain, perkara yang kelihatan benar dalam setiap sub-kumpulan boleh menjadi palsu apabila data tersebut diagregatkan tanpa memahami dengan baik konteks data.
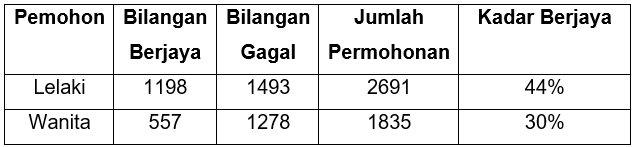
Satu contoh senario yang popular berkaitan fenomena paradoks Simpson ini ialah berkaitan data kemasukan pelajar siswazah di University of California, Berkeley pada tahun 1973 (Friendly & Meyer, 2015). Analisis statistik awal terhadap data ini mendapati kadar calon wanita yang berjaya diterima masuk (30%) adalah jauh lebih rendah berbanding calon pemohon lelaki (44%) (lihat Jadual 1). Hasil analisis ini membawa kepada tafsiran seolah-olah wujud diskriminasi jantina dalam pemilihan kemasukan ke universiti tersebut. Keputusan analisis ini boleh memberikan implikasi dan kesan yang buruk terhadap institusi tersebut
Jadual 1. Data kemasukan pelajar siswazah di University of California (1973)
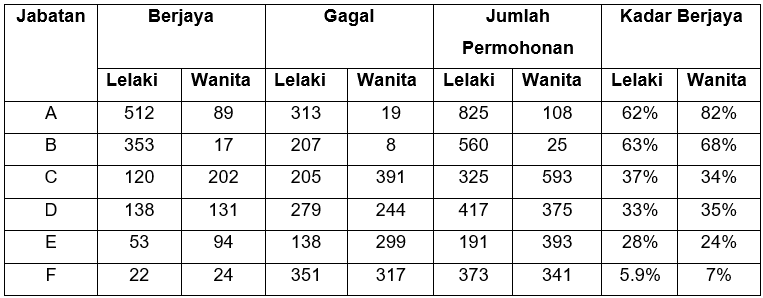
Namun, apabila penyelidik-penyelidik menganalisis dengan lebih mendalam data kemasukan tersebut mengikut kategori bagi setiap jabatan (lihat Jadual 2), mereka mendapati keputusan analisis awal tersebut adalah palsu dan tafsiran mengenai wujud diskriminasi jantina tersebut adalah tidak benar sama-sekali. Mereka mendapati, kebanyakan jabatan iaitu 4 daripada 6 jabatan yang terlibat, sebenarnya kadar calon wanita yang berjaya diterima masuk adalah lebih tinggi berbanding calon lelaki. Hanya di jabatan C dan E sahaja yang menunjukkan kadar calon lelaki yang berjaya diterima masuk didapati lebih sedikit berbanding calon wanita. Percanggahan ini berlaku kerana kebanyakan pemohon wanita adalah cenderung untuk memohon kemasukan ke jabatan yang lebih berdaya saing tinggi iaitu jabatan C dan E. Jabatan C dan E mempunyai kadar kegagalan yang lebih tinggi disebabkan syarat yang lebih ketat dan juga pemohonan yang lebih banyak. Sebaliknya, kebanyakan pemohon lelaki adalah cenderung untuk memohon kemasukan ke jabatan yang kurang berdaya saing seperti jabatan A dan B. Iaitu, jabatan A dan B mempunyai kadar kegagalan yang lebih rendah disebabkan syarat yang kurang ketat. Hakikatnya, kadar penerimaan keseluruhan bagi kemasukan ke universiti tersebut bukanlah dipengaruhi oleh faktor jantina, sebaliknya ianya bergantung kepada tahap kesukaran yang berbeza-beza merentasi jabatan.
Jadual 2. Data kemasukan pelajar siswazah mengikut jabatan.
Dalam senario ini, faktor “jabatan” merupakan pembolehubah tersembunyi yang penting untuk diperhalusi bagi memastikan hasil analisis yang diperolehi adalah tepat dan menggambarkan keadaan sebenar. Jika penganalisis terlepas pandang pembolehubah tersembunyi ini, secara mudah mereka akan memasuki perangkap paradoks Simpson (Geng, 2025).
Paradoks Simpson dalam Era Data Raya
Dalam persekitaran yang kaya dengan data hari ini, risiko untuk menghadapi perangkap paradoks Simpson adalah lebih tinggi. Set data raya yang besar pastinya memiliki ciri-ciri yang lebih heterogen dan kompleks, sekaligus menjadikannya lebih sukar untuk diuruskan terutama untuk mengenalpasti sub-kumpulan yang berpotensi menjadi pemboleh ubah tersembunyi. Implikasinya, penganalisis data akan lebih berisiko untuk membuat kesimpulan yang salah disebabkan kecelaruan yang gagal dikenalpasti diperingkat analisis. Dalam hal ini, paradoks Simpson sebenarnya memberi ingatan penting untuk kita menekankan perkara konteks (context matters) dalam data. Jika kita hanya melihat tingkah-laku data dalam struktur yang kasar, tanpa memahami dengan baik konteks data, kita mungkin akan terdedah dengan risiko membuat kesimpulan yang salah kerana terperangkap dalam fenomena paradoks Simpson. Inilah sebabnya mengapa disiplin dalam bidang statistik sering kali menegaskan untuk proses semakan data dibuat dengan teliti terlebih dahulu sebelum sebarang analisis statistik dijalankan untuk mencungkil maklumat daripada data. Antara tujuannya adalah untuk memecahkan set data kepada kategori-kategori yang membolehkan kita mengesan kewujudan pembolehubah tersembunyi ataupun faktor-faktor pembauran (pendam). Suatu ungkapan yang popular di kalangan ahli statistik ialah “nombor dan data tidak boleh bercakap untuk diri mereka sendiri”. Sebaliknya, ianya memerlukan tafsiran yang bijaksana. Namun, tafsiran yang bijaksana ini hanya akan diperolehi jika kita berjaya memahami dengan baik persoalan-persoalan asas seperti; mengapa data tersebut dicerap?, bagaimana ianya dicerap?, bagaimana data disusun atur?, apakah perkara konteks yang terkandung dalam data?, apakah wujud pemboleh ubah tersembunyi?, dan lain-lain isu. Semua ini tidak datang secara percuma. Ianya memerlukan asas ilmu yang baik berkaitan statistik dan data, disamping pengalaman dalam domain bidang yang diceburi.
Oleh kerana analisis data merupakan tugasan merentasi pelbagai bidang pekerjaan, maka implikasi fenomena paradoks Simpson ini adalah meluas. Sebagai contoh, dalam bidang penjagaan kesihatan, suatu rawatan mungkin kelihatan tidak berkesan bagi keseluruhan populasi, tetapi jika ianya diselidiki dengan lebih mendalam, rawatan tersebut berkemungkinan berkesan kepada kategori pesakit tertentu. Dalam bidang pengurusan pula, maklumat penunjuk prestasi utama (KPI) bagi suatu institusi secara umum mungkin menunjukkan tahap pencapaian yang tinggi, namun jika diselidiki dengan lebih teliti, kemungkinan pencapaian KPI ini hanya disumbang oleh kelompok tertentu dan bukannya keseluruhan staf. Begitu juga dalam bidang pembelajaran mesin, fenomena paradoks Simpson ini akan membawa input corak data yang mengelirukan dalam pembinaan model, sekaligus mengakibatkan model yang terhasil adalah pincang. Contoh-contoh ini memberi gambaran bahawa fenomena paradoks Simpson menekankan betapa pentingnya pemikiran kritis dan pemahaman konteks dalam tugasan berkaitan analisis data. Ini kerana, dalam dunia kini yang dipacu oleh data, maklumat yang tepat tidaklah hanya bergantung kepada seberapa banyak data yang kita ada, sebaliknya apa yang lebih penting ialah sejauh mana kita dapat memahami konteks data dan bagaimana kita boleh memberi tafsiran yang sewajarnya menerusi kaedah yang betul.
Bagaimana untuk Menangani Perangkap Paradoks Simpson?
Terdapat beberapa strategi yang boleh digunakan untuk menangani fenomena paradoks Simpson. Pertamanya, penyelidik perlu menilai dan menjalankan pembahagian data dengan teliti sebelum sebarang analisis lanjutan dijalankan. Pemecahan data kepada sub-kumpulan yang bermakna akan membantu penganalisis untuk mengesan corak yang mungkin disembunyikan oleh data. Penyelidik juga perlu menyemak dan mengesan jika wujud permboleh ubah tersembunyi yang boleh mempengaruhi keputusan analisis. Malah, pelbagai teknik-teknik pengvisualan boleh kita gunakan untuk mengesan ketidakkonsistenan antara pola keseluruhan dan sub-kumpulan dalam data. Semua pendekatan ini boleh memberikan gambaran awal terhadap kemungkinan kewujudan fenomena paradoks Simpson dalam data yang dikaji. Di samping itu, teknik penaakulan sebab-musabab (causal reasoning) juga merupakan pendekatan yang baik untuk mengenalpasti kewujudan fenomena paradoks Simpson. Ianya boleh dijalankan dengan memahami terlebih dahulu mekanisme asas yang mendorong kewujudan sebarang hubung-kait dalam data (Pearl, 2022). Selain itu, kaedah analisis sensitiviti merentas kumpulan juga merupakan pendekatan yang baik untuk menentusahkan kewujudan paradoks Simpson terhadap analisis data yang dijalankan.
Kesimpulannya, pengajaran yang boleh kita perolehi daripada fenomena paradoks Simpson ini ialah; tugasan analisis data bukanlah suatu tugasan yang remeh. Data yang besar berbantukan teknologi komputer yang canggih bukanlah suatu jaminan terhadap penghasilan maklumat yang tepat dan bermakna. Tanpa pemikiran yang kritis, pemahaman konteks, dan rasa skeptisisme yang tinggi dari diri penganalisis data, tugasan analisis data hanyalah akan menjadi suatu tugasan rutin yang tidak memberi impak yang sewajarnya.
Kredit foto utama-critikiddotcom
Rujukan:
Friendly, M., & Meyer, D. (2015). Discrete data analysis with R: visualization and modeling techniques for categorical and count data. CRC Press.
Pearl, J. (2022). Comment: understanding Simpson’s paradox. In Probabilistic and causal inference: The works of judea Pearl (pp. 399-412). Available at: https://dl.acm.org/doi/abs/10.1145/3501714.3501738
Geng, Z. (2025). Simpson Paradox. In International encyclopedia of statistical science (pp. 2335-2337). Berlin, Heidelberg: Springer Berlin Heidelberg.



{kind=link}